No, GraphQL Persisted Queries are not “Reinventing a REST API”
Persisted Queries?
Let’s start with a very quick primer on GraphQL persisted queries. A typical interaction between a GraphQL client and server looks a bit like this.
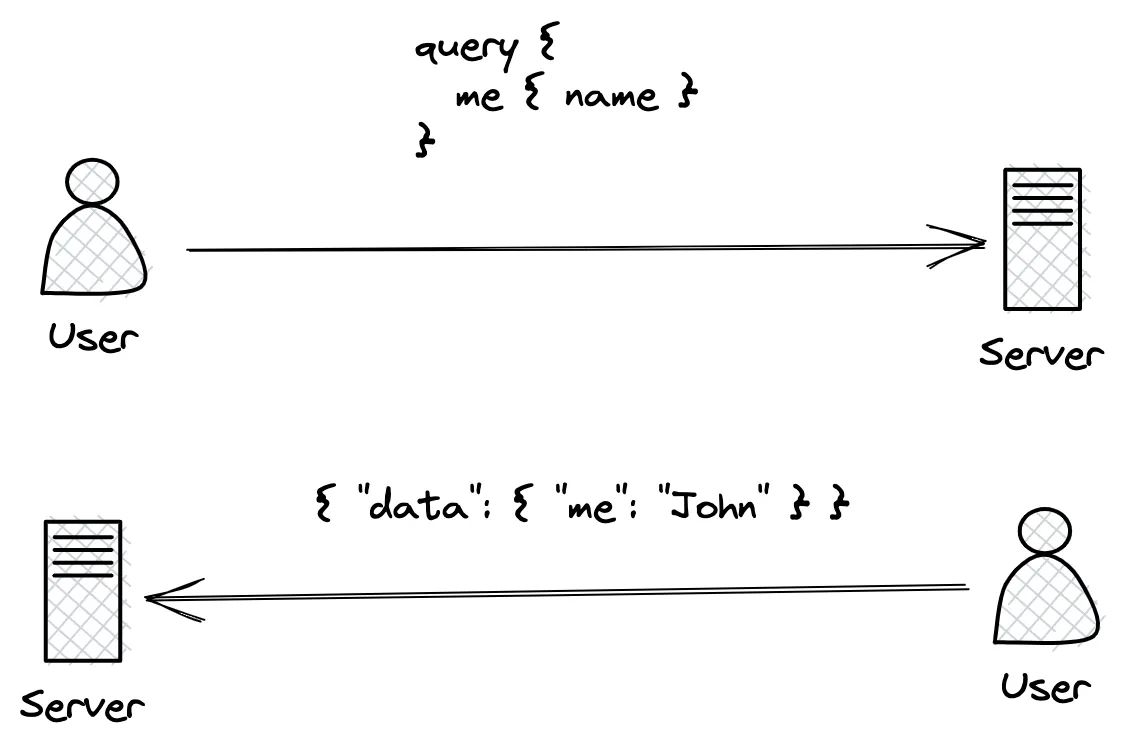
While this works perfectly well, there are certain downsides with query-based APIs:
- The request payload can grow large and is sent every single request, even though it rarely changes.
- While arbitrary queries are the goal during development when a client application is deployed, it is unnecessary to allow for all request variations.
This is where persisted queries come in. While they can be implemented in many ways, the general concept is this one:
- At build/release time, the client application exchanges its set of GraphQL documents with the server and gets a set identifier back.
- At runtime, the client only needs to send this identifier (plus variables) to execute a certain query. The query document itself is not sent, and is stored somewhere in server-land.
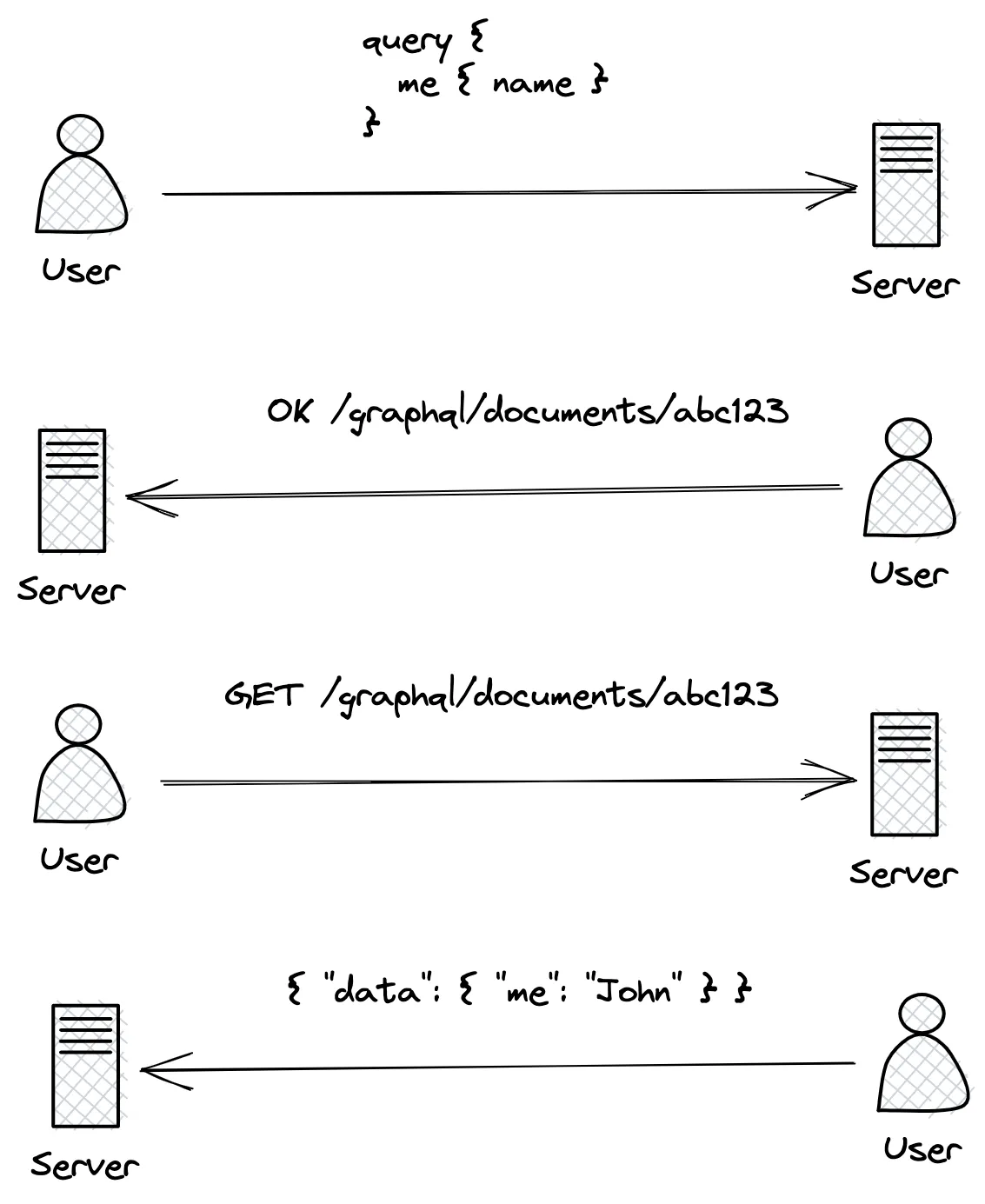
This solves the two problems we highlighted before:
- Clients don’t need to send those big GraphQL documents over the wire every time.
- The server only needs to validate them once (+ opportunity for lots of cool optimization)
- We can restrict to only using those identifiers and block arbitrary queries from getting executed.
Wait what?
Wait, you’re telling me we spent precious time building a GraphQL API just to land onGET /graphql/documents/abc123 ? This looks like we’ve just rebuilt a classic HTTP API, but not quite!
A lot of discussions about GraphQL go like this:
- Them: You can just submit any queries and take down or steal data from GraphQL APIs!
- You: Authorization is important to get right, we have tools and techniques like rate limiting/query complexity analysis to block queries that are too expensive, but also, you can use allow-listing with persisted queries to make sure arbitrary queries are not possible at runtime.
- Them: Ha! Gotcha! Persisted queries are basically just REST! You should have just built your API using REST in the first place.
- You: 🤦
Just to show you I’m not making this stuff up, here’s a collection of my favourites:

The first time you hear this line of reasoning, it definitely makes you think. I mean they’ve got a point, we’re really just issuing a GET to an HTTP resource. But we’re forgetting about the path we took to get there in the first place and a lot of the nuance that surrounds it.
The main mistake we make when we equate persisted queries with REST¹/typical HTTP APIs is that we are only looking at what happens at runtime between one client and the server.
The reality is that we kept a lot of the benefits of GraphQL when we built that client. The server team did not need to build a new client-specific resource or add to an existing one, making it more generic. In fact, if all the data was already in the schema, they did not have to do anything.
One of the problems GraphQL aims to solve is that when the number of different views, use cases, clients, and applications go up, traditional APIs can struggle with the tension between offering very specific APIs, making the maintenance of the API much harder over time, and maintaining a more generic API that can serve more of these use cases, but is less optimized for a single client. A lot of folks have hit this problem in the past. With GraphQL, the server can focus on building all the capabilities it supports through its schema, but clients can build their own exact requirements through the query language.
We did not lose any of those advantages with persisted queries. At development time, client teams can build view/app/use-case specific queries, any number of them, without worrying about server-side development and maintenance cost, but enjoy the simplicity and safety of a simple HTTP GET at runtime.
So saying that persisted queries are reinventing a simpler HTTP API or REST is not only false, but it’s also not a great “gotcha”. It allows us to keep some of the great sides of GraphQL while mitigating some of its weaknesses. What do we trade off for it? We add the complexity of a build process, although automated persisted queries get you pretty far already and are very simple to set up.
¹I didn’t want to go into it in the post, but, of course, it takes more than just resources and HTTP methods to make a REST API, so really, the comparison can’t stop there.
